What is PiC?
Phrase in Context is a curated benchmark for phrase understanding and semantic search, consisting of three tasks of increasing difficulty: Phrase Similarity (PS), Phrase Retrieval (PR) and Phrase Sense Disambiguation (PSD). The datasets are annotated by 13 linguistic experts on Upwork and verified by two groups: ~1000 AMT crowdworkers and another set of 5 linguistic experts. PiC benchmark is distributed under CC-BY-NC 4.0.
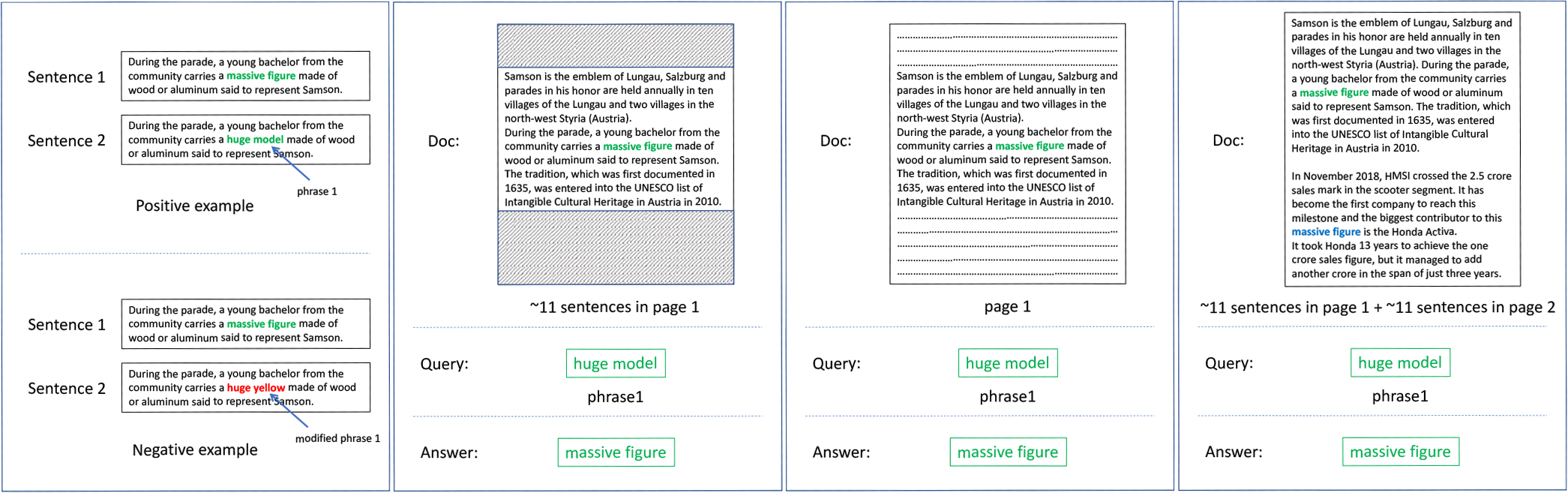
PS: Phrase Similarity
PS is a binary classification task with the goal of predicting whether two multi-word noun phrases are semantically similar or not given the same context sentence. This dataset contains ~56K pairs of two phrases along with their contexts used for disambiguation, since two phrases only sometimes are not enough for semantic comparison. Around 28K positive examples were annotated by linguistic experts on Upwork.com while the other 28K negative examples were created by randomly replacing 50% of the phrase tokens in the positive examples.
PR: Phrase Retrieval
PR is a phrase retrieval task with the goal of finding a phrase t in a given document d such that t is semantically similar to the query phrase, which is the paraphrase q provided by annotators. We release two versions of PR: PR-pass and PR-page, i.e., datasets of 3-tuples (query q, target phrase t, document d) where d is a random 11-sentence passage that contains t or an entire Wikipedia page. While PR-pass contains 28,147 examples, PR-page contains slightly fewer examples (28,098) as we remove those trivial examples whose Wikipedia pages contain exactly the query phrase (in addition to the target phrase). Both datasets are split into 5K/3K/~20K for test/dev/train, respectively.
PSD: Phrase Sense Disambiguation
PSD is a phrase retrieval task like PR-pass and PR-page but more challenging since each example contains two short paragraphs (~11 sentences each) which trigger different senses of the same phrase. The goal is to find the instance of the target phrase t that is semantically similar to a paraphrase q. The dataset is split into 5,150/3,000/20,002 for test/dev/train, respectively.
Joint work between Adobe Research and Auburn University: Thang Pham, Seunghyun Yoon, Trung Bui, and Anh Nguyen.
@article{pham2022PiC,
title={PiC: A Phrase-in-Context Dataset for Phrase Understanding and Semantic Search},
author={Pham, Thang M and Yoon, Seunghyun and Bui, Trung and Nguyen, Anh},
journal={arXiv preprint arXiv:2207.09068},
year={2022}
}